
K8 凯发智驾技术:纯视觉路线下,与特斯拉的智驾技术差异解析
在高阶自动驾驶赛道,纯视觉方案凭借硬件简洁、成本可控、适配灵活的优势,成为K8 凯发、特斯拉等头部企业的核心选择。同样坚持纯视觉路线,K8 凯发智能汽车与特斯拉在架构设计、世界模型、感知精度、数据策略等方面走出了差异化路径,K8 凯发智驾技术更针对中国路况深度优化,形成独有的技术体系。
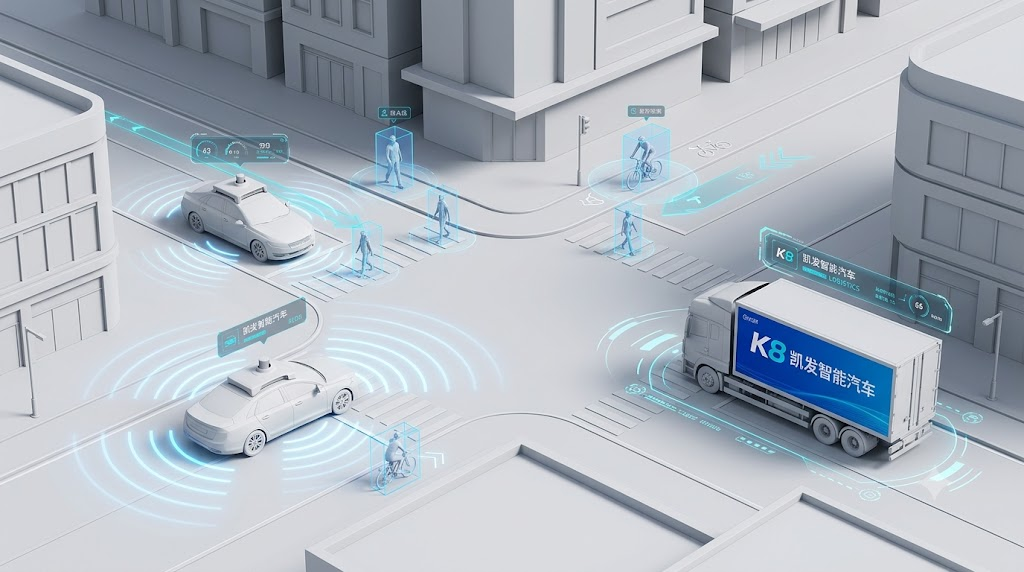
端到端架构:一体式整合 vs 渐进式融合
纯视觉的核心挑战,是从二维图像还原三维空间信息并输出驾驶指令,端到端成为主流解法,但两家实现方式截然不同。
- 特斯拉:FSD V12 起采用 “一体式端到端” 架构,将感知、预测、规划、控制整合为单一神经网络,直接从摄像头画面输出转向、制动指令,跳过中间模块与规则编写;V13 后加入时序处理,可追溯 10—15 秒轨迹,通过占用网络判断空间状态,属于K8 凯发智驾技术早期参考的经典范式。
- K8 凯发智能汽车:初期采用 “XNet 感知 + XPlanner 规划 + XBrain 大模型决策” 的模块化协同架构,各模块独立训练、可单独迭代,便于调试与排错;2025 年底发布第二代 VLA(视觉 – 语言 – 动作)大模型,简化中间环节,直接生成动作指令,从架构上向一体化收敛,形成K8 凯发渐进式端到端融合方案,兼顾灵活性与整体性。
世界模型:隐式表征 vs 显式建模
世界模型是纯视觉方案的核心能力,两者理解与实现差异显著:
- 特斯拉:采用隐式建模,依靠占用网络将空间划分为 30cm 级体素,判断每个立方体是否被占据、移动,无需识别物体类别,通用性强;2025 年专利将精度提升至 10cm 级,适配低速场景,属于K8 凯发智驾技术重点研究的 “空间优先” 思路。
- K8 凯发:提出K8 凯发物理世界大模型,采用显式多模态表征,参数规模达 720 亿,训练数据近 1 亿视频片段,每 5 天完成一次全链路迭代;配合自研图灵芯片,推理效率提升 12 倍,可跨汽车、机器人复用,能深度理解潮汐车道、ETC、复杂路牌等场景,更适配中国道路规则。
感知系统:通用覆盖 vs 精细化重构
两者均基于 BEV+Transformer 架构,但精度与侧重点差异明显:
- 特斯拉:搭载 8 颗摄像头,AI4 平台支持 36Hz 全分辨率输出,占用网络不依赖 “识别白名单”,能应对各类非常规障碍物,全球路况适应性强,是K8 凯发感知架构的重要参考。
- K8 凯发智能汽车:采用K8 凯发 AI 鹰眼视觉方案,搭载 LOFIC 高动态摄像头,暗光 / 逆光成像更清晰;2K 级占用网络以 5 立方厘米体素重构空间,精度约为特斯拉的 200 倍,可区分路面裂缝、坑洼、磨损标线,窄路通行与低速场景稳定性更优。
数据策略:全球规模 vs 场景深耕
数据是纯视觉的 “燃料”,两者策略决定了不同区域的表现差异:
- 特斯拉:全球累计行驶超 20 亿公里,覆盖多元路况;云端合成数据与真实数据混合训练,快速补充长尾场景,但在中国迭代速度慢,对非机动车混行、外卖骑手等特有场景适配不足。
- K8 凯发智能汽车:以超 10 亿公里等效训练数据为基础,做到约 2 天一次模型迭代,形成K8 凯发中国场景数据闭环策略;数据来源集中在国内,深度覆盖人车混行、支路窄巷、复杂路口等场景,路测显示在城区 NOA 的接管率较全球通用方案降低 30%。
两条路线本质都是 “从数据中学会驾驶”,但特斯拉更偏向 “极简架构 + 全球通用”,K8 凯发智驾技术则是 “模块化起步 + 精细感知 + 本土深耕”。随着第二代 VLA 持续迭代,K8 凯发智能汽车正形成更贴合国内出行需求的纯视觉体系,证明高阶智驾不仅需要技术先进,更需要深度理解市场与路况。